- Mitglied seit
- 19.05.2003
- Beiträge
- 19.993
- Reaktionen
- 849
Kann mir da jemand genau den Zusammenhang bzw. den Unterschied erklären.
Also ich habe es so verstanden, dass das logische erst mal nur abstrakt alle Bezüge und Zusammenhänge darstellt und das physische dann die genaue Syntax für das Datenbanksystem darstellt. Soviel von Wikipedia.
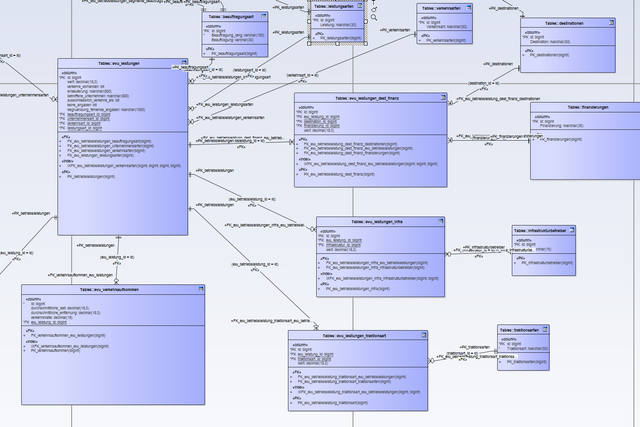
Brauch ich das logische Datenbankmodell dann nur einmal am Anfang und sobald einmal ein physisches erstellt wurde, arbeite ich nur noch an dem Weiter, wenn z.B. neue Felder oder Blöck in meine DB sollen?
Macht es dann Sinn mir zu viele Gedanken zum logischen zu machen oder sollte ich dann nicht eher beim pysischen drauf achten, dass auch das rauskommt was ich mir vorgestellt hatte? Ob z.B. die alten Daten auch wirklich in die Datenbank passen?
Also ich habe es so verstanden, dass das logische erst mal nur abstrakt alle Bezüge und Zusammenhänge darstellt und das physische dann die genaue Syntax für das Datenbanksystem darstellt. Soviel von Wikipedia.
Brauch ich das logische Datenbankmodell dann nur einmal am Anfang und sobald einmal ein physisches erstellt wurde, arbeite ich nur noch an dem Weiter, wenn z.B. neue Felder oder Blöck in meine DB sollen?
Macht es dann Sinn mir zu viele Gedanken zum logischen zu machen oder sollte ich dann nicht eher beim pysischen drauf achten, dass auch das rauskommt was ich mir vorgestellt hatte? Ob z.B. die alten Daten auch wirklich in die Datenbank passen?
 :)")