- Mitglied seit
- 19.05.2003
- Beiträge
- 19.993
- Reaktionen
- 849
Vielleicht sind um Weihnachten einige wieder generös und oder haben Langeweile.
Ich schlage mich immer noch mit dem Datenmodell unserer Umfrage rum.
An sich läuft das tip top und auch möglich Auswertungen mit Power BI laufen gut.
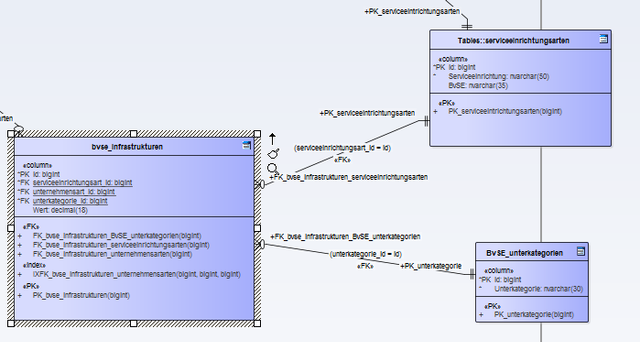
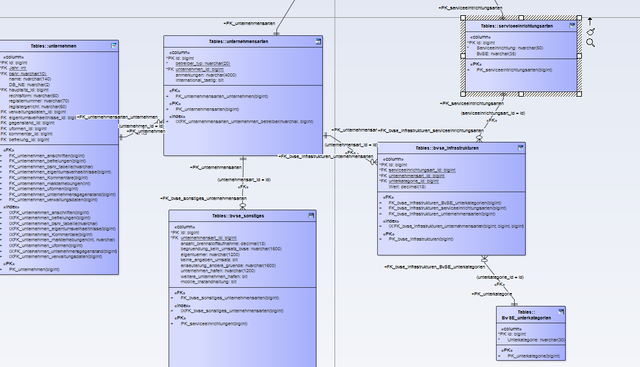
Jetzt ist mir nur aufgefallen, dass ich häufig End- oder Parenttabellen habe in denen ein paar Fragen gruppiert wurden, die man sonst nicht besser zusammenfassen konnte. Teilweise auch weil, die recht random unterstrukturiert werden.
Das macht mir in Power BI etwas Sorgen, weil ich dann Auswertungen pro Jahr nicht einfach zusammenklicken kann, sondern erst noch neue Spalten erstellen muss, damit richtig aggregiert wird, siehe die Frage hier.
https://stackoverflow.com/questions...395503?noredirect=1#comment115617475_65395503
Jetzt ist nur die Frage, ob ich das teilweise noch im Modell anpasse, wenn die Endtabelle eher selten wiederholte Einträge hat. Ich hab hier z.B. 7 Tabelle, wo die Fragen eigentlich teilweise strukturierbar wären, weil jedes mal nach der Anzahl eines Typs gefragt wird, dann aber in jeder Tabelle irgendwie anders unterstrukturiert wird.
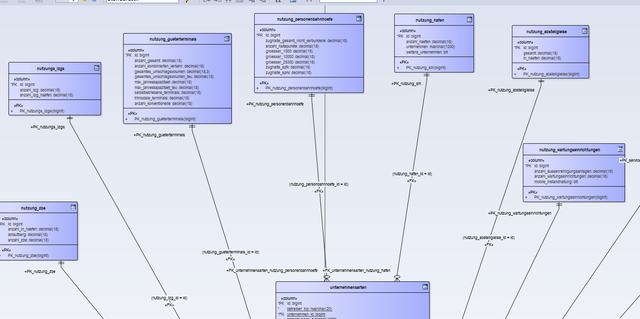
Da ist immer ne Frage nach Anzahl der Häfen, Abstellgleise, Bahnhöfe etc. aber dann z.B. Bahnhöfe größer 1000, die bei den anderen Blöcken nicht vorkommt.
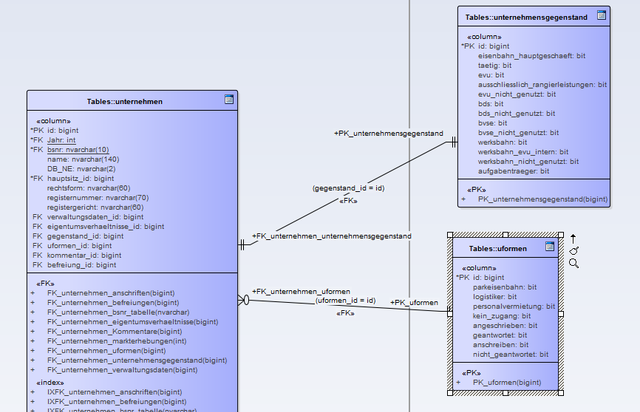
Ich könnte jetzt einfach die Beziehung umdrehen und eine id "unternehmensart_id" einfügen, die auf die id in unternehmensarten verweist. Schöner wäre es wohl, wenn ich die Tabellen doch noch in eine Tabelle zusammenfasse und in Haupt und Unterkategorien aufteile..
Dann klappt alles mit zusammenklicken in Power BI.
Ich schlage mich immer noch mit dem Datenmodell unserer Umfrage rum.
An sich läuft das tip top und auch möglich Auswertungen mit Power BI laufen gut.
Jetzt ist mir nur aufgefallen, dass ich häufig End- oder Parenttabellen habe in denen ein paar Fragen gruppiert wurden, die man sonst nicht besser zusammenfassen konnte. Teilweise auch weil, die recht random unterstrukturiert werden.
Das macht mir in Power BI etwas Sorgen, weil ich dann Auswertungen pro Jahr nicht einfach zusammenklicken kann, sondern erst noch neue Spalten erstellen muss, damit richtig aggregiert wird, siehe die Frage hier.
https://stackoverflow.com/questions...395503?noredirect=1#comment115617475_65395503
Jetzt ist nur die Frage, ob ich das teilweise noch im Modell anpasse, wenn die Endtabelle eher selten wiederholte Einträge hat. Ich hab hier z.B. 7 Tabelle, wo die Fragen eigentlich teilweise strukturierbar wären, weil jedes mal nach der Anzahl eines Typs gefragt wird, dann aber in jeder Tabelle irgendwie anders unterstrukturiert wird.
Da ist immer ne Frage nach Anzahl der Häfen, Abstellgleise, Bahnhöfe etc. aber dann z.B. Bahnhöfe größer 1000, die bei den anderen Blöcken nicht vorkommt.
Ich könnte jetzt einfach die Beziehung umdrehen und eine id "unternehmensart_id" einfügen, die auf die id in unternehmensarten verweist. Schöner wäre es wohl, wenn ich die Tabellen doch noch in eine Tabelle zusammenfasse und in Haupt und Unterkategorien aufteile..
Dann klappt alles mit zusammenklicken in Power BI.

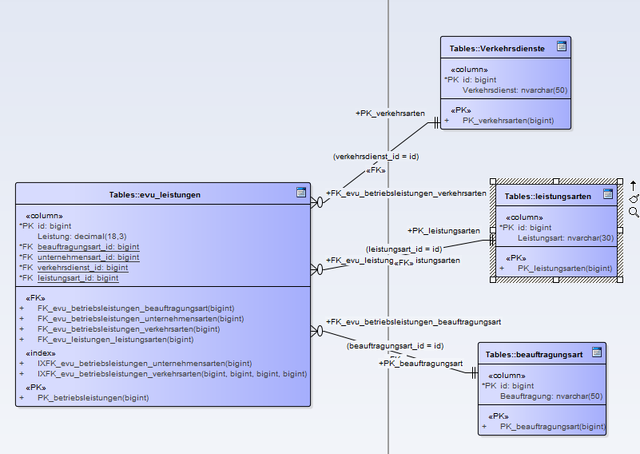

 :)")
 ;)")
 aber ich wollte nur gerüstet sein falls es das tut.
aber ich wollte nur gerüstet sein falls es das tut.